Die KI-Systeme von OpenAI und Google sind leistungsstark. Wohin führen sie uns?

Was sollten wir von großen Sprachmodellen (LLMs) halten? Das ist im wahrsten Sinne des Wortes eine Milliarden-Dollar-Frage.
Dieses Thema wurde diese Woche in einer Analyse des ehemaligen OpenAI-Mitarbeiters Leopold Aschenbrenner behandelt. Er argumentiert darin, dass wir möglicherweise in wenigen Jahren von einer allgemeinen Intelligenz auf Basis großer Sprachmodelle entfernt sind, die als „Drop-in-Remote-Mitarbeiter“ alle Aufgaben erledigen kann, die menschliche Remote-Mitarbeiter erledigen. (Er meint, dass wir vorankommen und diese Intelligenz entwickeln müssen, damit China nicht als Erster ankommt.)
Seine (sehr lange, aber lesenswerte) Analyse fasst einen Gedankengang zu großen Sprachmodellen wie ChatGPT gut zusammen: dass es sich bei ihnen um eine Larvenform der künstlichen allgemeinen Intelligenz (AGI) handelt und dass ihre notorischen Fehler größtenteils verschwinden werden, wenn wir immer umfangreichere Trainingsläufe durchführen und mehr darüber lernen, wie wir sie feinabstimmen und anregen können.
Diese Ansicht wird manchmal mit dem Satz „Skalierung ist alles, was Sie brauchen“ umschrieben, was mehr Trainingsdaten und mehr Rechenleistung bedeutet. GPT-2 war nicht sehr gut, aber das größere GPT-3 war viel besser, das noch größere GPT-4 ist noch besser, und wir sollten grundsätzlich davon ausgehen, dass sich dieser Trend fortsetzt. Sie möchten sich beschweren, dass große Sprachmodelle einfach nicht gut für etwas sind? Warten Sie einfach, bis wir ein größeres haben. (Offenlegung: Vox Media ist einer von mehreren Verlagen, die Partnerschaftsvereinbarungen mit OpenAI unterzeichnet haben. Unsere Berichterstattung bleibt redaktionell unabhängig.)
Zu den prominentesten Skeptikern dieser Sichtweise zählen zwei KI-Experten, die sich sonst selten einig sind: Yann LeCun, Leiter der KI-Forschung bei Facebook, und Gary Marcus, Professor an der New York University und lautstarker LLM-Skeptiker. Sie argumentieren, dass einige der Mängel von LLMs – ihre Schwierigkeiten bei logischen Denkaufgaben, ihre Neigung zu „Halluzinationen“ – mit zunehmender Größe nicht verschwinden. Sie erwarten in Zukunft abnehmende Erträge aus der Größenzunahme und sagen, dass wir wahrscheinlich keine vollständig allgemeine künstliche Intelligenz erreichen werden, wenn wir unsere derzeitigen Methoden einfach mit Milliarden von Dollar verdoppeln.
Wer hat Recht? Ehrlich gesagt glaube ich, dass beide Seiten völlig übermütig sind.
Durch die Skalierung sind LLMs in einer Vielzahl kognitiver Aufgaben viel besser, und es scheint verfrüht und manchmal absichtlich ignorant zu behaupten, dass dieser Trend plötzlich aufhören wird. Ich berichte nun schon seit sechs Jahren über KI und höre immer wieder Skeptiker behaupten, dass es einige einfache Aufgaben gibt, die LLMs nicht erledigen können und nie erledigen können werden, weil sie „echte Intelligenz“ erfordern. Wie am Schnürchen findet Jahre (oder manchmal nur Monate) später jemand heraus, wie man LLMs dazu bringt, genau diese Aufgabe zu erledigen.
Früher habe ich von Experten gehört, dass Programmieren eine Sache sei, für die Deep Learning niemals geeignet sei. Heute ist es einer der stärksten Aspekte von LLMs. Wenn ich jemanden höre, der voller Überzeugung behauptet, dass LLMs eine komplexe Denkaufgabe nicht bewältigen können, merke ich mir diese Behauptung. Ziemlich oft stellt sich sofort heraus, dass GPT-4 oder seine Top-Konkurrenten es doch können.
Ich halte die Skeptiker tendenziell für nachdenklich und ihre Kritik für vernünftig, doch ihre ausgesprochen gemischte Erfolgsbilanz veranlasst mich zu der Annahme, dass sie ihrer Skepsis gegenüber skeptischer sein sollten.
Wir wissen nicht, wie weit uns die Größe bringen kann
Was die Leute angeht, die es für sehr wahrscheinlich halten, dass wir in ein paar Jahren über künstliche Intelligenz verfügen werden, so ist mein Gefühl, dass auch sie ihre Argumente übertreiben. Aschenbrenners Argumentation wird durch die folgende Grafik veranschaulicht:
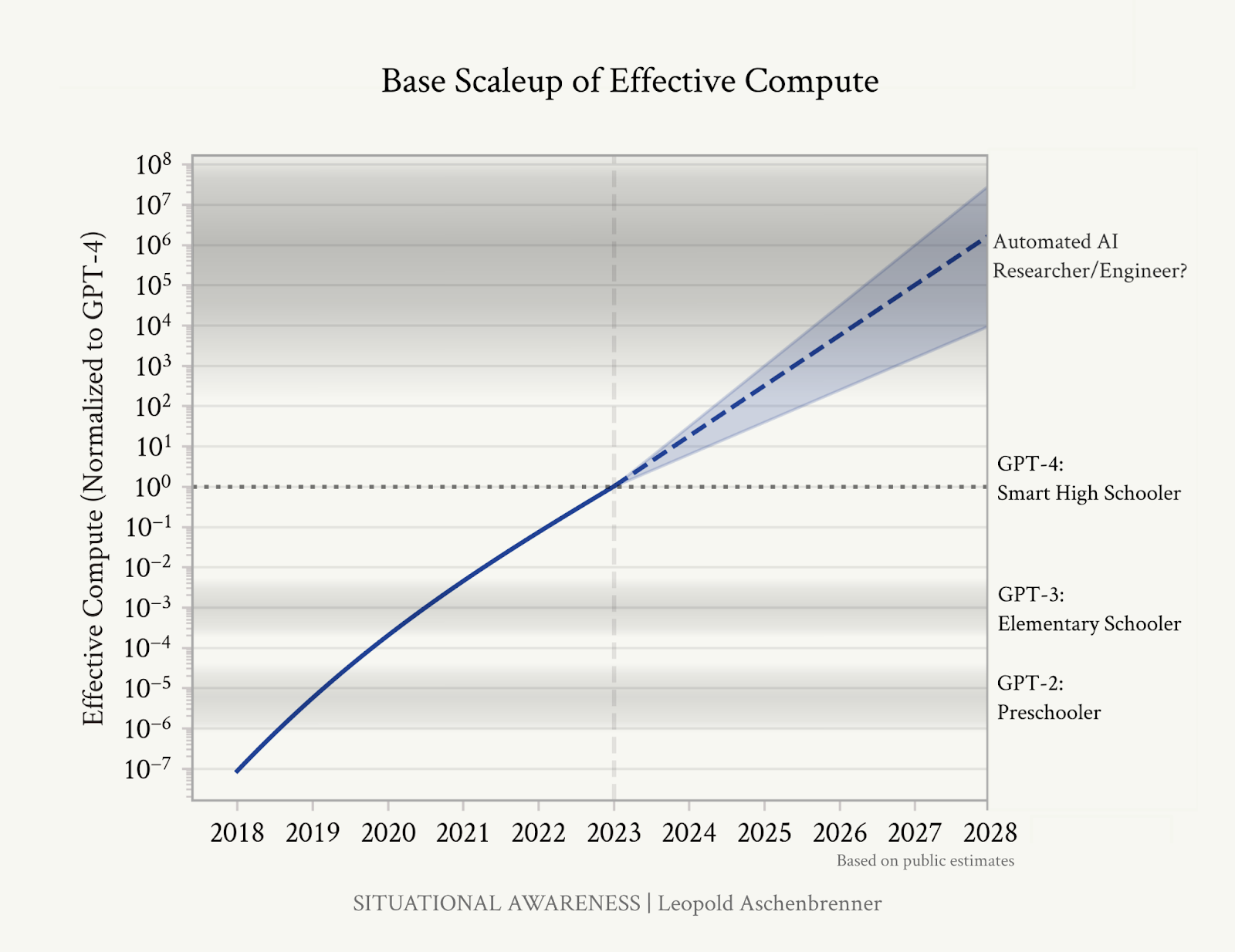
Ich möchte den Ansatz „gerade Linien in einem Diagramm“ zur Vorhersage der Zukunft nicht völlig schlecht machen; zumindest ist die Möglichkeit „die aktuellen Trends setzen sich fort“ immer eine erwägenswerte Möglichkeit. Aber ich möchte darauf hinweisen (und andere Kritiker haben das auch getan), dass die rechte Achse hier … völlig erfunden ist.
GPT-2 ist in keiner Hinsicht einem menschlichen Vorschulkind gleichwertig. GPT-3 ist bei den meisten akademischen Aufgaben viel besser als Grundschüler und natürlich viel schlechter als sie, wenn es beispielsweise darum geht, durch ein paar Begegnungen eine neue Fähigkeit zu erlernen. LLMs sind in ihren Gesprächen und Interaktionen mit uns manchmal täuschend menschlich, aber im Grunde sind sie nicht sehr menschlich; sie haben unterschiedliche Stärken und Schwächen, und es ist sehr schwierig, ihre Fähigkeiten durch direkte Vergleiche mit Menschen zu erfassen.
Darüber hinaus haben wir keine Ahnung, wo in dieser Grafik der „automatisierte KI-Forscher/-Ingenieur“ hingehört. Sind dafür so viele Fortschritte nötig wie für den Übergang von GPT-3 zu GPT-4? Doppelt so viele? Sind dafür Fortschritte nötig, die es beim Übergang von GPT-3 zu GPT-4 nicht gegeben hat? Warum sollte man ihn sechs Größenordnungen höher einordnen als GPT-4 statt fünf, sieben oder zehn?
„AGI bis 2027 ist plausibel … weil wir zu ignorant sind, es auszuschließen … weil wir keine Ahnung haben, wie weit es auf der Y-Achse dieser Grafik bis zur Forschung auf menschlichem Niveau ist“, antwortete der KI-Sicherheitsforscher und -Aktivist Eliezer Yudkowsky Aschenbrenner.
Diese Haltung kann ich viel besser nachvollziehen. Da wir kaum wissen, welche Probleme LLMs in größerem Maßstab lösen können, können wir nicht mit Sicherheit sagen, was sie leisten können, bevor wir sie überhaupt gesehen haben. Das bedeutet aber auch, dass wir nicht mit Sicherheit sagen können, welche Fähigkeiten sie haben werden.
Vorhersagen sind schwierig – vor allem, wenn sie die Zukunft betreffen
Es ist außerordentlich schwierig, die Fähigkeiten von Technologien vorherzusehen, die es noch nicht gibt. Die meisten Leute, die das in den letzten Jahren versucht haben, haben sich blamiert. Aus diesem Grund neigen die Forscher und Denker, die ich am meisten respektiere, dazu, ein breites Spektrum an Möglichkeiten zu betonen.
Vielleicht bleiben die enormen Verbesserungen im allgemeinen Denkvermögen, die wir zwischen GPT-3 und GPT-4 gesehen haben, bestehen, wenn wir die Modelle weiter skalieren. Vielleicht auch nicht, aber wir werden dennoch enorme Verbesserungen in den effektiven Fähigkeiten von KI-Modellen sehen, weil wir sie besser nutzen: Wir entwickeln Systeme zum Umgang mit Halluzinationen, überprüfen Modellergebnisse gegeneinander und optimieren Modelle besser, um uns nützliche Antworten zu geben.
Vielleicht bauen wir allgemein intelligente Systeme, die LLMs als Komponente haben. Oder vielleicht wird OpenAIs mit Spannung erwartetes GPT-5 eine riesige Enttäuschung sein, die den Hype um KI zum Platzen bringt und die Forscher vor die Aufgabe stellt, herauszufinden, welche kommerziell wertvollen Systeme gebaut werden können, ohne dass in naher Zukunft große Verbesserungen in Sicht sind.
Entscheidend ist, dass man nicht glauben muss, dass AGI wahrscheinlich erst 2027 kommt, um zu glauben, dass die Möglichkeit und die damit verbundenen politischen Implikationen ernst zu nehmen sind. Ich denke, dass die Grundzüge des Szenarios, das Aschenbrenner skizziert – in dem ein KI-Unternehmen ein KI-System entwickelt, mit dem es die interne KI-Forschung aggressiv weiter automatisieren kann, was zu einer Welt führt, in der eine kleine Anzahl von Menschen mit einer großen Anzahl von KI-Assistenten und -Dienern weltverändernde Projekte in einer Geschwindigkeit verfolgen kann, die kaum Kontrolle zulässt – eine reale und beängstigende Möglichkeit sind. Viele Menschen geben zig Milliarden Dollar aus, um diese Welt so schnell wie möglich zu verwirklichen, und viele von ihnen glauben, dass sie in naher Zukunft liegt.
Das ist eine sachliche Diskussion und eine sachliche politische Reaktion wert, selbst wenn wir meinen, dass die Vorreiter in Sachen KI zu selbstsicher sind. Marcus schreibt über Aschenbrenner – und ich stimme zu –: „Wenn Sie sein Manuskript lesen, lesen Sie es bitte wegen seiner Bedenken hinsichtlich unserer mangelnden Vorbereitung, nicht wegen seiner sensationslüsternen Zeitpläne. Die Sache ist, wir sollten besorgt sein, egal, wie viel Zeit uns bleibt.“
Doch die Diskussion wird erfolgreicher und die politische Reaktion wird besser auf die Situation zugeschnitten sein, wenn wir offen darüber sprechen, wie wenig wir wissen – und wenn wir diese Verwirrung als Anstoß nehmen, die für uns wichtigen Aspekte der KI besser zu messen und vorherzusagen.
Eine Version dieser Geschichte erschien ursprünglich im Future Perfect-Newsletter. Melden Sie sich hier an!

